개선 배경
이전 포스트 ELB AccessLog Partitioning 적용하기를 통해 엑세스 로그 파티셔닝 후 사용하는 과정에서 겪었던 불편한 점에 대해 정리하고, 이에 대한 개선사항 및 과정들을 소개합니다.
사용 간 겪었던 문제 (1)
시간 단위의 파티셔닝 부재
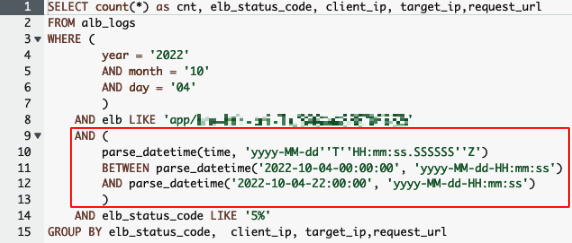
일 단위까지만 파티셔닝을 적용했기에 시간 단위의 분석이 필요한 경우, 아래와 같이 쿼리를 통해 시간을 매번 별도로 지정하여 사용하거나 다운로드 받은 csv 파일 내에서 데이터 필터링을 통해 확인해야하는 한계가 존재했습니다.
![Untitled]()
Timezone 관련 혼동 발생
사용하는 Timezone이 달라 로그 분석에 익숙하지 않은 팀원 분이 잘못된 시간대의 로그를 분석하는 경우가 종종 있었습니다.![Untitled]()
- UTC
- S3 버킷에 저장되는 객체 이름에 표기되는 시간
- S3 버킷에 저장되는 LoadBalancer AccessLog 자체의 저장 시간
- KST
- S3 버킷에 저장되는 LoadBalancer Access Log 마지막 수정 시간
- 실제 분석 시 사용하는 시간
- UTC
Prefix별 파티셔닝의 필요성
AWS에서 제공하는 S3 버킷 내 Access Log 저장 경로는 아래와 같으며, 저장할 S3 버킷 외 다른 Prefix는 변경이 불가능합니다.
s3://[Bucket Name]/AWSLogs/[AccountID]/elasticloadbalancing/ap-northeast-2/2023/01/09/
하지만 아래와 같이 여러 고객사에서 엑세스 로그를 저장하는 케이스는 매우 다양했으며, 변경 불가능한 Prefix에 대한 처리가 필요했습니다.
- 하나의 버킷에 2개 이상의 로드밸런서 엑세스 로그를 저장
- 여러 리전에 로드밸런서가 생성하여 사용
- 여러 어카운트의 엑세스 로그를 하나의 어카운트에 저장

개선 사항 도출 및 구성
Lambda를 이용한 엑세스 로그 분할
아래와 같은 개선 사항 적용을 위해 S3 버킷 내 엑세스 로그가 저장될 때 트리거되는 Lambda를 통해 개선이 필요한 사항이 반영된 Prefix로 변환 후 저장되도록 구현했습니다. 이를 통해 로그 분석 간 소요되는 불필요한 시간을 줄일 수 있게 되었습니다.
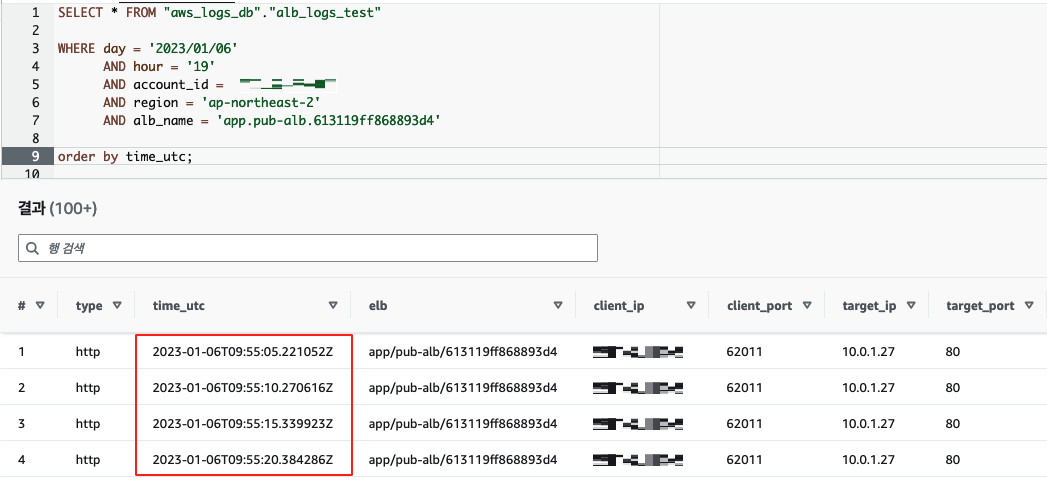
시간 단위까지 파티셔닝 세분화 기본 저장 경로는 ‘일’까지만 저장되는데, 로그 분석 시 시간 단위까지의 분석이 필요한 경우가 대부분이었습니다. 이를 해결하기 위해 Prefix를 추가하여 시간 단위까지 저장되도록 설정했습니다.
Timezone 통일 분석 편의를 위해 UTC로 표기되는 객체 이름 내 시간을 KST로 변경했습니다. → 날짜와 시간의 표기에 관한 국제 표준 규격(ISO 8601)에 따라 파일명 시간대 표기부분에 Z대신 +09:00을 표기합니다(ex. 20230101T0015+09:00).
Prefix별 파티셔닝 세분화 고객사별 다양한 케이스에 대응할 수 있도록 Account ID와 Region, 로드밸런서 이름 항목에 대한 파티셔닝을 추가로 설정하였습니다.
Lambda 코드
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50
import boto3 import json from datetime import datetime from datetime import timedelta # default_path : AWSLogs/111111111111/elasticloadbalancing/ap-northeast-2/2023/01/01/객체명 # ALB key : 111111111111_elasticloadbalancing_ap-northeast-2_app.pub-alb.82eb6fb7f7a90413_20210609T0000Z_10.10.17.197_ok8s9v7n.log.gz # CLB key : 111111111111_elasticloadbalancing_ap-northeast-2_pub-clb_20230102T0300Z_10.10.2.125_15h4vyln.log def lambda_handler(event, context): client = boto3.client('s3') for record in event['Records']: bucket_name = record['s3']['bucket']['name'] default_path = record['s3']['object']['key'] object_name = default_path.rsplit('/', 1)[-1] # get items with localizing timezone splitted_list = object_name.split('_') account_id = splitted_list[0] service = splitted_list[1] region = splitted_list[2] lb_name = splitted_list[3] kst_date = datetime.strptime(splitted_list[4], "%Y%m%dT%H%MZ") + timedelta(hours=9) # Check if minute is '00' if splitted_list[4][-3:-1] == '00': # 20230106T19 00 Z kst_date -= timedelta(hours=1) year = kst_date.strftime("%Y") month = kst_date.strftime("%m") day = kst_date.strftime("%d") hour = kst_date.strftime("%H") # localizing timezone in object name splitted_list[4] = kst_date.strftime("%Y%m%dT%H%M") + "+09:00" localized_object_name = '_'.join(map(str, splitted_list)) partitioned_path = f"AWSLogs/{account_id}/{service}/{region}/{lb_name}/{year}/{month}/{day}/{hour}/{localized_object_name}" print(partitioned_path) response = client.copy_object( Bucket = bucket_name, Key = partitioned_path, CopySource = bucket_name + '/' + default_path ) response = client.delete_object( Bucket = bucket_name, Key = default_path )
- Line 13~16 : S3 트리거를 통해 받은 레코드에서 버킷과 객체 이름을 추출합니다.
- Line 19~33 : 객체 이름에서 파티셔닝할 항목들을 구분하여 저장합니다. 시간대의 경우 KST로 변환하여 저장합니다.
- Line 27~28 : 엑세스 로그 특성 상 객체 이름에 표기되는 시간 기준 5분 전의 로그가 저장되므로, 정각에 저장되는 로그는 이전 시간 디렉터리로 저장되도록 합니다.
- Line 36~40 : 개선 사항들을 적용한 객체 이름과 변환된 경로를 생성합니다.
- Line 42~51 : 기존 객체의 이름을 변경하고 변환된 경로로 이동한 후 삭제합니다.
Lambda 호출 비용 계산 - 월 0.04 USD
![Untitled]()

구성 간 발생했던 문제와 해결 방법
엑세스 로그 저장 방식
개선 사항 적용 후 19시~20시에 저장된 로그에 대해 쿼리 실행을 통해 테스트하던 도중, 저장 시간이 18시인 로그가 확인되어 분석을 진행했습니다.
![Untitled]()
S3 버킷에 저장되는 엑세스 로그는 5분 주기로 저장됩니다. 예를 들어 객체 이름에 표기되는 시간이
20230106T1900Z와 같이 정각인 객체에 저장되는 로그는18:55:00 ~ 18:59:59까지의 로그가 저장됩니다. 따라서 이 경우에 해당하는 객체는 이전 시간 디렉터리에 저장하도록 처리하는 코드를 추가했습니다.1 2 3 4 5 6
kst_date = datetime.strptime(splitted_list[4], "%Y%m%dT%H%MZ") + timedelta(hours=9) ... # Check if minute is '00' if splitted_list[4][-3:-1] == '00': # 20230106T19 00 Z kst_date -= timedelta(hours=1) ...
Lambda 중복 실행 문제
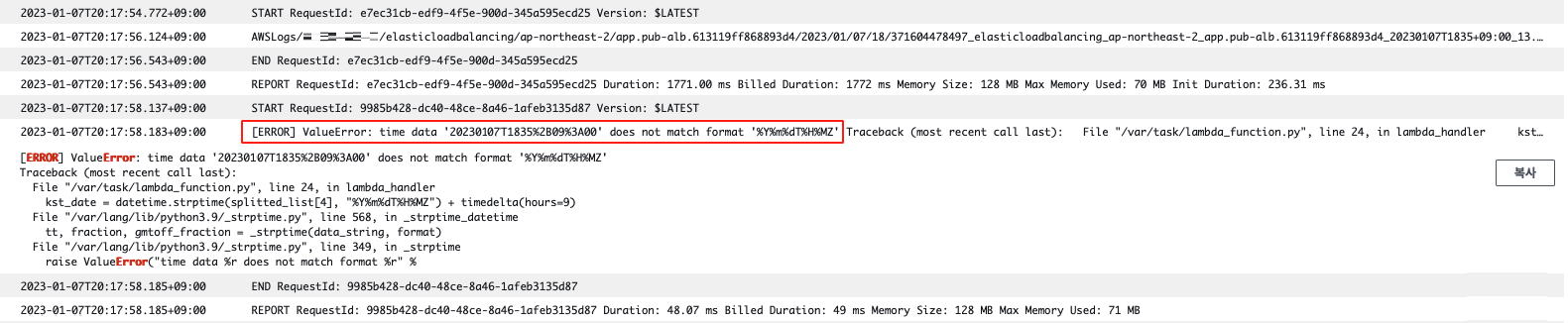
코드 내 문제가 없음에도 문자열을 datatime 형으로 변환하는 부분에서 형식이 맞지 않다는 오류가 발생했습니다.
![Untitled]()
디버깅 결과, 받은 문자열이 이미 KST 변환이 이루어진 상태로 형변환이 시도되면서 발생한 오류로 확인하였고 Lambda를 트리거하는 S3 이벤트가 모든 객체 생성에 대해 트리거되도록 설정한 것이 문제였습니다.
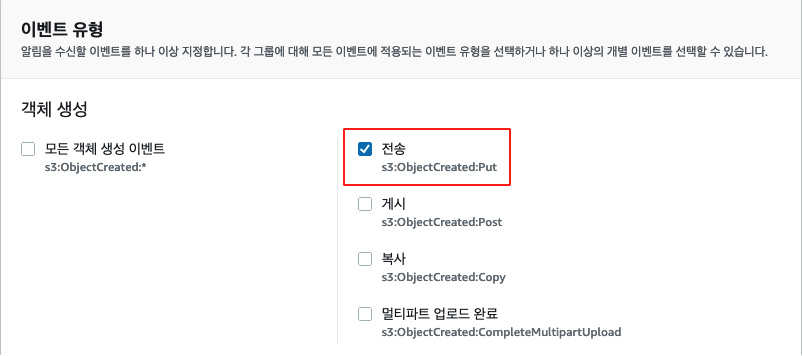
아래와 같이 Put 시에만 트리거되도록 설정하여 해결했습니다.
![Untitled]()
다음 포스트 LoadBalancer AccessLog Partitioning 개선하기 (2)에서 이어집니다.